Question 1
(Mixed Questions)
DRAG DROP
You are building an intelligent solution using machine learning models.
The environment must support the following requirements:
![]() Data scientists must build notebooks in a cloud environment
Data scientists must build notebooks in a cloud environment
![]() Data scientists must use automatic feature engineering and model building in machine learning pipelines.
Data scientists must use automatic feature engineering and model building in machine learning pipelines.
![]() Notebooks must be deployed to retrain using Spark instances with dynamic worker allocation.
Notebooks must be deployed to retrain using Spark instances with dynamic worker allocation. ![]() Notebooks must be exportable to be version controlled locally.
Notebooks must be exportable to be version controlled locally.
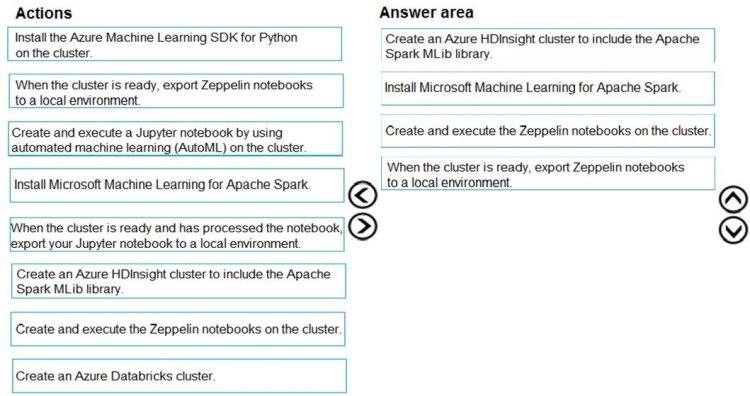
You need to create the environment.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:
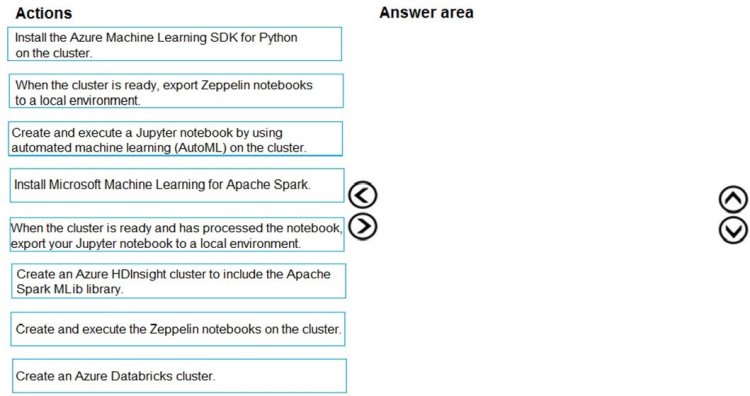
Answer is in the explanation below.