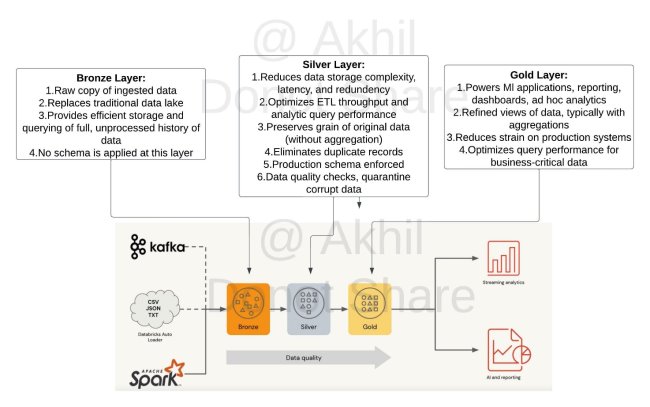
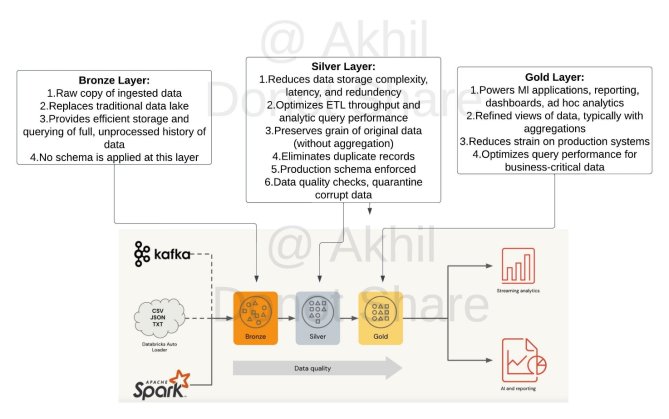
Question 4
What is the main difference between the silver layer and gold layer in medallion architecture?
Select an option, then click Submit answer.
-
○
Silver optimized to perform ETL, Gold is optimized query performance
-
○
Gold is optimized go perform ETL, Silver is optimized for query performance
-
○
Silver is copy of Bronze, Gold is a copy of Silver
-
○
Silver is stored in Delta Lake, Gold is stored in memory
-
○
Silver may contain aggregated data, gold may preserve the granularity of original data